On this page
The /build phase in our agentic workflow solution, VGV Wingspan, ends by running a panel of review agents in parallel, each checking the work against a different standard before a PR opens. We wired that panel by hand. Claude Code can now write that kind of orchestration script on its own, which means every phase of a session can fan out the way the review phase already does. That is the shift this post is about, and it is a set of Claude Code best practices we have been running against real Flutter monorepos rather than a forecast.
What Changed in Claude Code: Dynamic Workflow Orchestration
The old model is one agent that plans and executes inside a single context window. That works for most coding. It breaks down on work that is wide, long-running, and adversarial, the kind where one mind has to hold too much at once and ends up cutting corners.
The new model is different. Claude can now write a JavaScript orchestration script on the fly, spawns parallel subagents, each with its own clean context, and verifies the results before they reach you. The orchestrator can route each subagent to a different model and run it in its own git worktree, so the work is isolated end to end. For Flutter teams that is the detail that matters, because a monorepo change touches scattered files that should not step on each other.
We will not re-explain the whole mechanic here. You can read Anthropic’s announcement of dynamic workflows in Claude Code for the invocation syntax and the research-preview details. The capability is the native primitive for the fan-out orchestration we already hand-build in VGV Wingspan, our open-source agentic engineering workflow for Claude Code, and that is the connection worth drawing out.
Three Failure Modes That Break Flutter Agentic Sessions
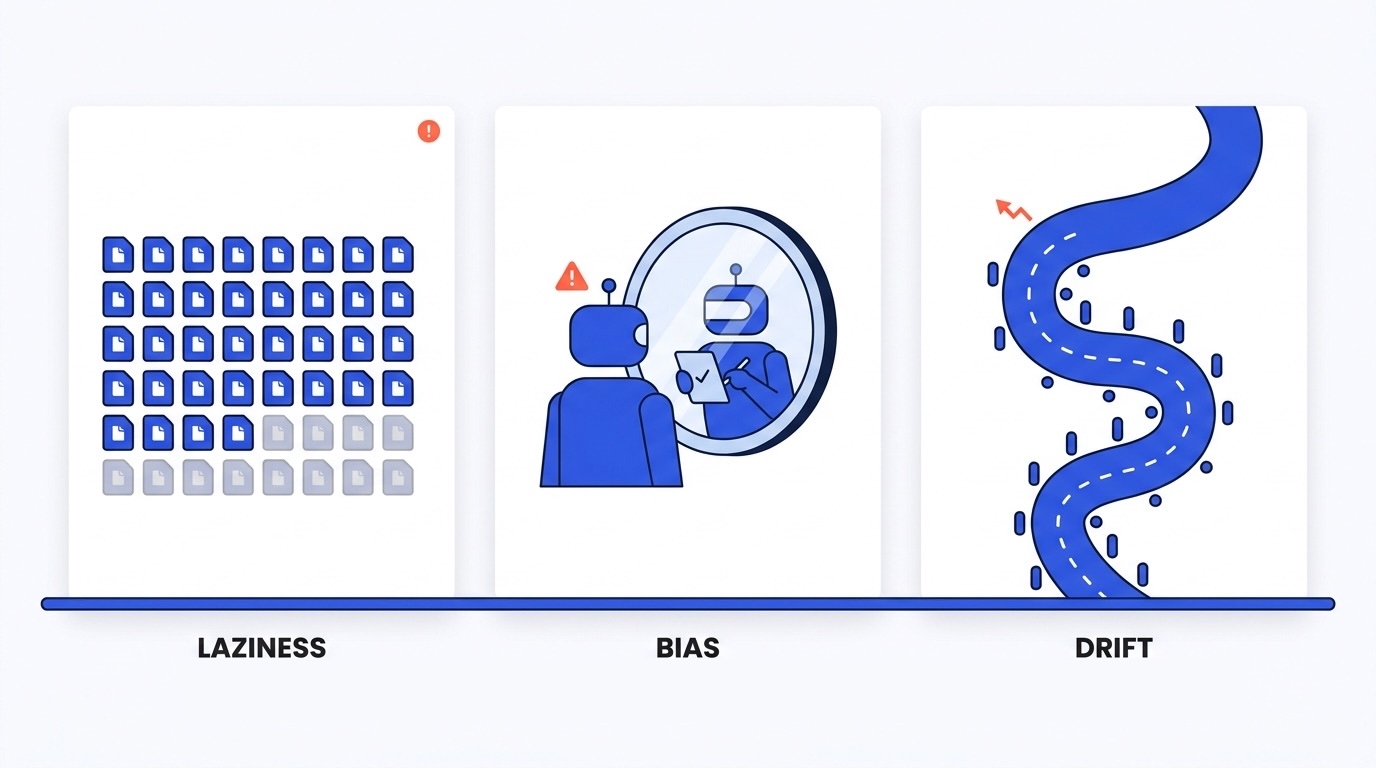
A single agent on a large Flutter codebase tends to fail in three ways. Anthropic names them, and they map cleanly onto the work we see.
Agentic laziness is the first. The agent stops after 35 of 50 files and calls it done. That is the exact failure mode on a monorepo-wide change, where the last fifteen files are the ones nobody wants to touch.
Self-preferential bias is the second. The agent trusts its own output when asked to verify it, which is the central risk when a tool reviews the code it just wrote. The review reads clean because the same context produced both the work and the verdict.
Goal drift is the third. A long session loses the original constraints after the context compacts. An edge-case rule that mattered at the start of the session gets quietly abandoned halfway through, and nobody notices until a bug report arrives.
Dynamic workflows counter all three structurally. Each unit gets an isolated context, and an independent verifier checks it. The decision rule that falls out of this is simple. Wide beats deep. Reach for a workflow when a task is wide, parallel, and needs per-unit judgment. The workflow patterns underneath are documented in the workflow patterns Anthropic describes, and the rest of this post maps them onto real Flutter work.
Where Dynamic Workflows Pay Off on a Flutter Codebase
Three kinds of work on a large Flutter codebase reward this approach the most. Each one teaches a pattern, not just an example.
Breaking-Change Migrations Across a Flutter Codebase
This is the home turf for fan-out-and-synthesize plus adversarial verification in worktrees. A go_router or flutter_bloc major update, a Material 2 to Material 3 move, an SDK bump, a sweep from manual JSON to freezed. The unit of fan-out is the call site, the failing test, or the package. The orchestrator spawns one subagent per fix in its own worktree, runs an adversarial reviewer against each fix, then synthesizes and merges. A CI gate runs after the merge, the same one a human PR would hit.
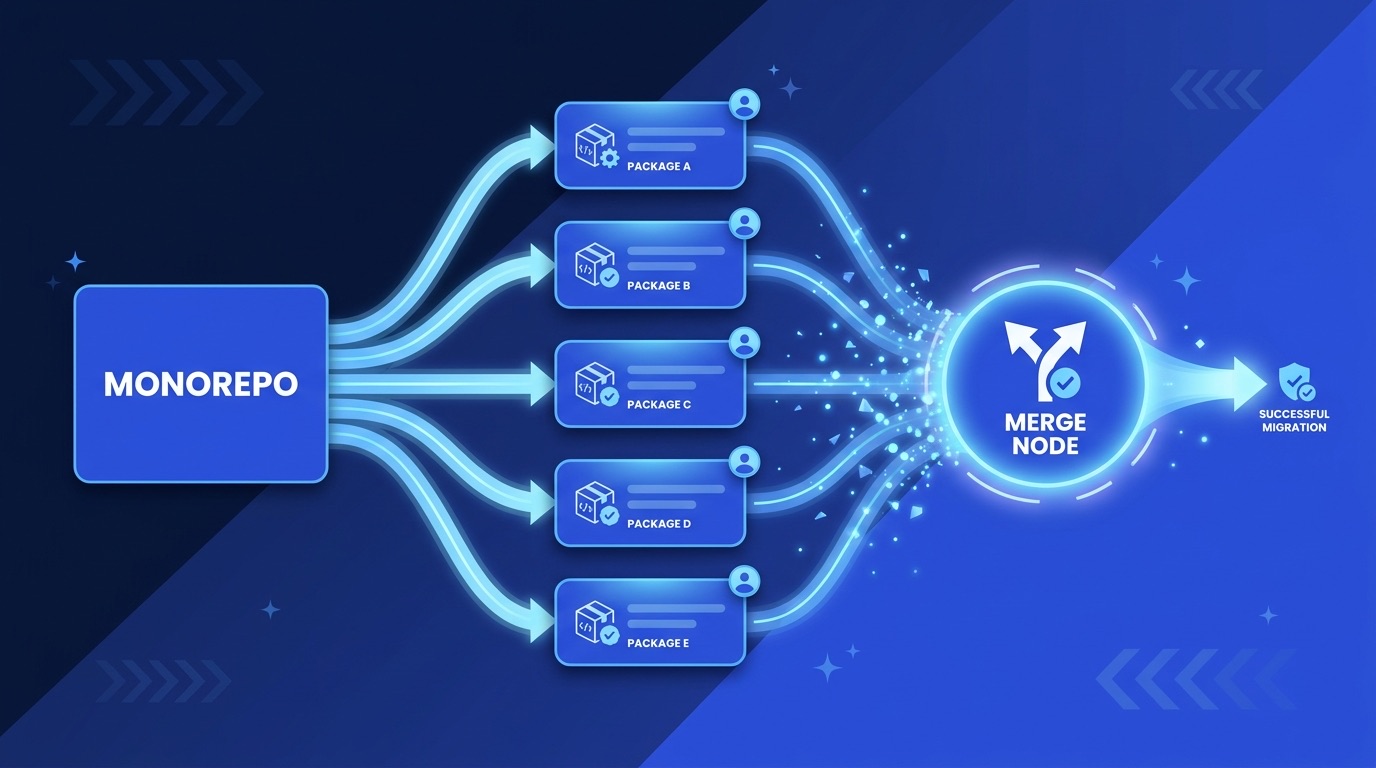
The shape looks like this.
// Pseudo-workflow: Material 2 to 3 migration across a Flutter codebase
for (const package of affectedPackages) {
spawnAgent({
worktree: package.name,
task: "migrate_material_2_to_3",
codebase: package.source,
verifier: adversarialReviewer({ rubric: material3_compat }),
});
}
await synthesizeAndMerge(results);The proof that this scales past toy examples is public. Jarred Sumner’s thread on the Bun Rust port documents a large rewrite that used dynamic workflows for the fan-out. That is an external proof point at a scale most Flutter monorepos never reach, which is the point. If the pattern holds at that scale, a package migration is well within range.
Correctness and Leak Sweeps
This is fan-out plus loop-until-done plus analyzer verification. Undisposed AnimationController, TextEditingController, FocusNode, and StreamSubscription instances. Unclosed Bloc and Cubit instances. BuildContext used across an async gap without a mounted check. Missing const. These are scattered, individually small, and exactly the work a single agent gets lazy about. A workflow fans the sweep across the widget tree, loops each fix until the analyzer is clean, and verifies against the analyzer rather than against its own judgment.
Test and Golden Coverage with a Skeptic in the Loop
This is adversarial verification, and it targets the pump-and-pass risk. A widget test can pump a frame and pass without asserting anything real. One agent writes the test. A second agent checks it against a rubric for real behavioral assertions, loading and error states, and whether the golden actually moves when the widget changes. The second agent never sees the first agent as trustworthy, which is the entire point. This is Flutter testing best practices enforced by an independent reader instead of by hope.
Deepening Every Wingspan Phase with Dynamic Workflows
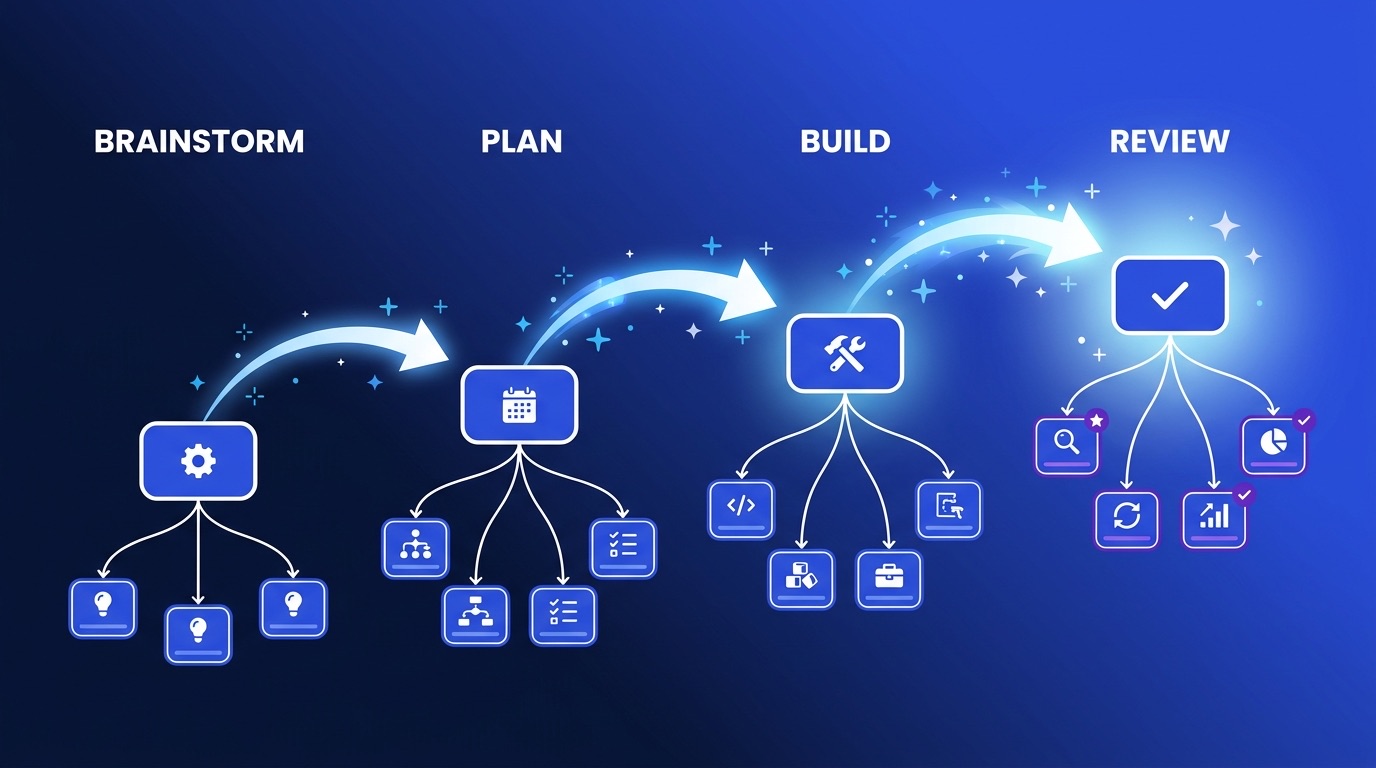
This is where it gets interesting for the way we work. VGV Wingspan structures a session into four phases: /brainstorm, /plan, /build, and /review. The build phase already runs a panel of review agents in parallel after the build phase, which we documented while shipping a stretch of apps on the workflow. Dynamic workflows are the native primitive for that fan-out, and the same primitive is available to the other three phases today. You invoke a workflow inside the phase. Wingspan does not generate it for you yet, but nothing stops you from taking any phase wider right now.
Brainstorm: Generate, Filter, and Run a Tournament
Today a brainstorm explores the problem space and proposes approaches with tradeoffs from one context. With a workflow, independent agents each commit to a different approach from a clean context, probe the codebase, the design, and the data layer separately for gaps, and then a judge ranks them against a rubric and synthesizes. The depth comes from independence. One context weighing three options is weaker than three contexts each defending one, because the single context shares its blind spots across all three options while the independent agents do not.
// Pseudo-workflow: brainstorm tournament, one approach per isolated context
const approaches = await Promise.all([
spawnAgent({ context: "fresh", commitTo: "approach_a" }),
spawnAgent({ context: "fresh", commitTo: "approach_b" }),
spawnAgent({ context: "fresh", commitTo: "approach_c" }),
]);
const ranked = await judge(approaches, { rubric: tradeoffs });Independent agents widen the net. An approach that one context would never have surfaced gets a defender, and the judge has to reckon with it.
Plan: Fan Out Research, Then Verify Against the Code
The plan phase researches the existing codebase, identifies patterns, and flags gaps. A workflow fans that research out, one agent per module or package with its own context, synthesizes the findings into a file-level plan, then runs a verifier that checks the plan against the code before a line is written. The oversized-plan problem is a context problem, and fan-out research is the structural fix. A single context that has read everything tends to plan for everything. A set of focused contexts plans for what is actually there.
Build: Fan Out Per Unit in Worktrees
For a large change, the build phase spawns per-file or per-unit subagents in worktrees, the migration pattern from the section above. The number and shape of the agents adapts to the change instead of being fixed in advance. A two-file fix gets two agents. A package migration gets one per package.
Review: One Verifier per Standard
The parallel review panel generalizes. One verifier per standard, coverage, accessibility, performance, and the VGV rules, each in its own isolated context. This is AI code review done so that the reviewer is not the author. Self-preferential bias is the named risk when a tool reviews its own work, and isolated-context verification is the answer. The accessibility verifier is a concrete example. Our accessibility skill that maps findings to WCAG 2.2 criteria is exactly the per-standard reviewer this phase wants. The discipline carries the same caveat we wrote up in what changes about code review when AI writes your code: a panel that approves itself is not enough, and human review still targets judgment over checklists.
The payoff is the compounding. Wingspan’s design thesis is that each phase makes the next one better, a behavior we documented across a run of apps on the workflow. A sharper brainstorm yields a sharper plan, which yields a build that already knows which files to touch. Dynamic workflows deepen each phase, so that compounding gets stronger end to end.
When Not to Reach for a Fleet
Token cost is real, and this is a research preview. Start scoped. A small feature build does not need twenty agents. Most day-to-day tickets do not need a panel of five reviewers, let alone fifty. As a rough calibration, a fifty-file migration might run on the order of tens of agents, not hundreds. Match the fleet to the surface area of the change.
Determinism matters too. For a pure mechanical rename, dart fix or a custom lint plus codemod is cheaper and more auditable. Use a workflow when each unit needs judgment, not when a regex, or a static workflow would do.
There is a trust boundary. For triaging user-reported bugs or other external input, such as a bug description pasted from a customer ticket or a third-party API response, use the quarantine pattern. Agents that read untrusted content do not get high-privilege actions.
And the review discipline does not change. A merged PR from a subagent swarm still needs a human owner. For teams with the right constraints, the patterns pay off, and the way we think about Wingspan changes with them.
How VGV Thinks About Agentic Engineering
VGV Wingspan was built on hand-wired orchestration. Every harness had to be written in advance, generic enough to cover the cases we expected. The shift is that Claude can now generate a harness tailor-made for the task in front of it.
The skills layer encodes which pattern each task deserves. A phase generates a workflow when the work is wide and high-value, and stays lean when it is not. We have done this concretely already. Our Figma-to-Flutter skill with golden tests and Widgetbook validation packages domain-specific judgment into something repeatable, which is the same move at a smaller scale.



