Not long after adopting AI-assisted development at VGV, I approved a PR with thousands of additions. I did look at the code. But at that scale, the review shifted — I was not checking the fundamentals anymore. I was scanning for something that looked obviously wrong. That is a different activity, and it misses a lot. Not because you are not paying attention, but because the volume forces you into a different mode entirely.
That PR is not a failure of discipline. It is what happens when generation speed and scope discipline are not in sync. An AI-assisted build session can produce in a few hours what used to take weeks. Without new habits around how that output gets structured into reviewable units, PRs reach sizes that turn code review into a formality.
And a PR that size is not just slow to review — it is impossible to review properly. Human reviewers can only absorb a limited amount of unfamiliar code at a time. Reviewing a diff that size properly would take days of focused effort. Nobody has days. What actually happens: you scan the file list, check the areas you know best, verify the automated signals are green, and approve. Every architectural decision embedded in those lines goes unchallenged.
The downstream costs are real. Decisions nobody questioned compound over months. Bugs a careful reviewer would have caught ship. The knowledge transfer that happens when a reviewer asks “why did you approach it this way?” never occurs. And when something breaks, tracing it back through a 17k-line merge is its own archaeology project.
Big PRs do not just slow down review. They degrade the value of the review process itself — turning a quality gate into a checkbox.
We still believe small PRs are the right default. Not because of a rule — because a PR one person can hold in their head is a PR that gets a real review. AI generation does not change that belief. It just makes it harder to act on.
When Wingspan’s /build command finishes, it has already run five review agents in parallel: architecture, VGV standards, test quality, code simplicity, and PR readiness. The VGV AI Flutter Plugin has been running dart analyze and dart format after every file edit throughout the build. Minor issues get auto-fixed. By the time a PR opens, a significant portion of what used to be human review work has already happened.
So the question is not “should I review AI-generated code?” The question is: given how much the toolchain already checks, what does human review actually do now?
What the Toolchain Handles
Understanding what is already covered is the starting point. Spending reviewer time on things the toolchain catches is the first inefficiency to eliminate.
The VGV AI Flutter Plugin operates on two levels. Its skills — /vgv-bloc, /vgv-testing, /vgv-layered-architecture, /vgv-accessibility, and others — guide Claude during generation, baking VGV conventions directly into the code being written: sealed classes for BLoC events, mocktail for mocks, blocTest for unit tests, four-layer architecture with unidirectional dependencies. The code does not need to be corrected for these patterns after the fact because the plugin taught Claude to produce them correctly in the first place. Its PostToolUse hooks then run dart analyze and dart format after every single file edit, so lint violations and formatting issues are resolved inline, not in review.
Wingspan’s build phase adds a review layer on top of that. After all code is generated, it runs five agents in parallel before the PR opens:
- VGV standards agent — naming conventions, state immutability, layer separation
- Architecture review agent — dependency direction, layer boundary violations
- Test quality review agent — coverage, naming, anti-patterns like
pumpAndSettleon infinite animations - Code simplicity agent — YAGNI violations, premature abstractions, unnecessary complexity
- PR readiness agent — merge readiness, missing acceptance criteria, coverage gaps
Minor issues are auto-fixed. Important ones are surfaced and resolved before the PR is created. The consolidated output looks something like this:
Build Review Summary
Architecture Review Agent
✅ Layer boundaries respected. Data → Repository → BLoC → Presentation
with unidirectional dependencies throughout.
VGV Standards Agent
⚠️ UserProfileState: copyWith missing for errorMessage field. Auto-fixed.
Test Quality Agent
✅ All BLoC events covered by blocTest.
✅ No pumpAndSettle calls on infinite animations.
Code Simplicity Agent
⚠️ UserProfileRepository: fetchUser and fetchUserById share identical
implementations. Consolidated to one method. Auto-fixed.
PR Readiness Agent
✅ All acceptance criteria from the plan are implemented.
✅ No scope creep beyond the plan specification.
2 issues auto-fixed. PR is ready to open.By the time a reviewer opens the PR, this pipeline has already run.
This does not mean human review is optional. It means the review conversation can move up the stack.
AI Removes the Effort Signal
Before AI tools, PR size was a proxy for effort. A reasonably scoped PR meant someone spent real time on it, internalized every trade-off, and understood every decision they made. Reviewers calibrated their depth accordingly — a multi-day PR got serious scrutiny, a quick fix got a lighter pass.
AI breaks this signal entirely. A feature that would have taken days to write manually — repository, multiple BLoCs, several screens, a full test suite — comes out of Wingspan’s build in a fraction of that time. Nobody spent days thinking through every decision. The developer reviewed the output in their editor, accepted what looked right, and opened the PR.
A reviewer who treats that PR with the same depth as a multi-day effort is doing the right thing. The instinct is to treat the short turnaround as a signal of simplicity. It is not. The automated agents caught what they can catch. What they cannot catch is whether the decisions embedded in all that generated code reflect what the team actually agreed to do.
This pressure does not go away regardless of how many agents run. Human review is often the first scrutiny the decisions in a PR receive from someone who did not generate it.
Review the Plan, Not Just the Code
The most underused quality gate in an AI-assisted workflow is the plan. Wingspan saves implementation plans to docs/plan/ before a single line of code is generated. The /plan-technical-review skill validates a plan for scope, technical soundness, and whether it will produce a reviewable PR — before /build runs.
This is where scope discipline belongs. If a plan says “add UserProfile feature and refactor the Repository pattern,” that is two plans. Splitting it before /build runs takes minutes. Untangling it at PR review — where the code is already written, the tests pass, and rejecting the PR means blocking the feature — takes hours and usually ends in a soft approval anyway. The difference between those two outcomes is one early conversation and one compromised quality gate.
The rule: one PR, one axis of change. A new feature is one axis. Refactoring an existing pattern is one axis. Mixing them is two plans. When you see a Wingspan plan that covers both, split it before /build runs.
Reading docs/plan/ before reviewing the PR also tells you what the build was supposed to do. If you were not involved in the planning conversation, treat the plan as the first thing to review, not a given. Do the acceptance criteria make sense for the feature? Is the scope right? Checking that the implementation matches the plan is only meaningful if the plan itself holds up.
What Human Review Still Owns
With five automated agents and a hooks-enforced style pipeline, two things remain that no tool can handle.
Verifying the build matched the plan. The automated agents check whether the code is good. Only a human can check whether the code does what the plan said it should. Compare the PR diff against the plan’s acceptance criteria. Did the build cover every task? Did scope creep in — a model change that quietly refactored how that model is used in three other places? Changes outside the plan’s scope should either go into their own PR or be explicitly justified in the PR description.
Team decisions that no agent can encode. The five review agents enforce patterns that can be expressed in code: architecture boundaries, test coverage, VGV standards. They cannot enforce decisions that exist only in your team’s memory. These are what regress silently when AI generates code that is correct but misaligned. Three categories where this shows up consistently:
Code behavior preferences
How your code signals failure, handles errors, or manages control flow. Agents verify that error handling exists — not that it matches your team’s chosen pattern.
Wingspan generated a fetchUser implementation using a sealed result type — a pattern common in the broader Dart ecosystem. The tests matched with exhaustive pattern matching, so they passed. The architecture agent approved the layer separation. But the team convention is to use exceptions for expected failure cases:
// Generated — compiles, tests pass, agents approve
Future<Either<Failure, User>> fetchUser(String id) async {
try {
final user = await _api.getUser(id);
return Right(user);
} catch (e) {
return Left(NetworkFailure(e.toString()));
}
}
// Convention — throw exceptions, not result types
Future<User> fetchUser(String id) async {
try {
return await _api.getUser(id);
} catch (e) {
throw NetworkException(e.toString());
}
}The reviewer caught it because they knew the convention. If it had shipped, callers would use exhaustive pattern matching where the team expects a try/catch.
Once caught, the fix is not just to correct the PR — it is to write the convention down so Wingspan never generates the wrong pattern again. A CLAUDE.md entry at the project root takes precedence over the skill’s defaults:
## Error handling
Use exceptions for expected failure cases in repositories — not result or sealed types.On the next build, Wingspan reads this before generating any repository code. The skill provides the baseline; the project entry overrides it. The convention stops being something a reviewer has to remember and becomes something the AI enforces from the start.
UX behavior preferences
How state transitions feel to the user — decisions made in design discussions that exist nowhere in the code’s type system.
Wingspan emitted const UserProfileState(status: UserProfileStatus.loading), clearing the user field on refresh. The state transition is valid. But the team decision is that loading states carry the previous data so the screen does not flash blank:
// Generated — valid state transition, no agent flags it
emit(const UserProfileState(status: UserProfileStatus.loading));
// Convention — preserve previous data during refresh
emit(state.copyWith(status: UserProfileStatus.loading));No agent flags a valid state transition. The reviewer caught it because they remembered the UX decision.
Layer responsibility
What logic belongs in which layer. Agents enforce that layers do not import each other incorrectly — not that logic is in the right place within a valid import boundary.
Wingspan put display formatting directly in a Text widget. It compiled, passed analysis, passed all five agents. But the team rule is that derived display data belongs in the model or a dedicated formatter, not in the widget:
// Generated — compiles, passes all agents
Text('${user.firstName} ${user.lastName}'.trim())
// Convention — display formatting belongs in the model or a formatter
Text(state.user.displayName)A reviewer caught it on the second read.
None of these are obscure edge cases. They are the kind of decisions every team makes and rarely writes down.
This second category is also an opportunity. Every time a reviewer catches a decision the agent missed, that decision should be written down. A CLAUDE.md file at the project root is the right place — both Wingspan and the VGV AI Flutter Plugin read it during generation, so documented decisions feed directly into what the AI writes next time.
The New Shape of Review
The checklist changes when the toolchain is in place.
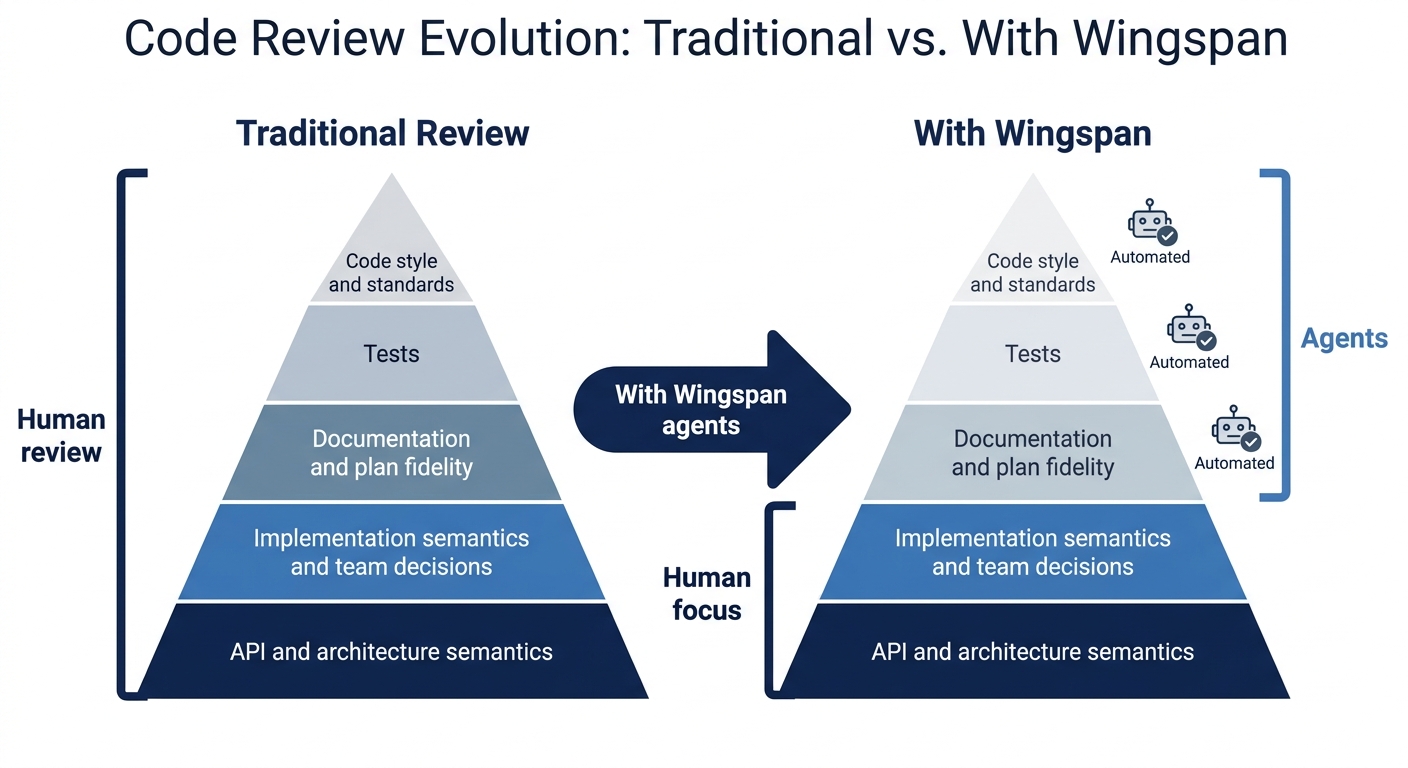
Stop spending time on: formatting, import ordering, missing const, lint violations, naming that follows standard Dart conventions, standard VGV architecture patterns. These are caught before the PR opens.
Spend time on:
Plan-to-code fidelity — does the PR match what the plan specified?
Scope — are there changes outside the plan? Should they be a separate PR?
Team-specific decisions — does the code follow conventions your team holds that are not in any agent’s ruleset?
The build phase review summary — Wingspan surfaces what its agents flagged and how they were resolved. Read it. If an agent flagged an architecture concern and it was auto-fixed, verify the fix makes sense. Trust but verify.
Agent behavior — go one level further. If an agent approved something it should have caught, or flagged something incorrectly, that is signal worth capturing. A pattern the architecture agent consistently misses belongs in your project-wide agent settings. A false positive that keeps surfacing is a prompt to tighten the agent’s scope. The agents improve when reviewers treat gaps as feedback, not just noise.
The Quality Gate Is Still Yours
Wingspan and the VGV AI Flutter Plugin do not remove the need for code review. They move the quality gates earlier and automate what can be automated, which is more than most teams realize.
What remains is genuinely human work: validating intent against the plan, enforcing decisions that live in your team’s context, and making the judgment calls that no agent has the information to make. That work does not compress just because the generation was fast. If anything, it matters more — because the code is generated faster than any team can internalize, and review is where the team’s decisions actually get applied.



